This note followed Josh's awesome video1 to implement a neural network simulating the all-or-none law of action potentials using pytorch. Additionally, to understand the computations behind the training, I have organized the "computation process" and "source code verification" in this note.
The code comes from Josh's video. See the original video here. Thanks to Josh for his high-quality, easy-to-understand videos and for supporting this article!🎉 Triple Bam!!!
The human brain is composed of hundreds of billions of nerve cells, also known as neurons. These neurons are specialized cells that transmit electrical signals. When receptors on the cell surface receive neurotransmitters, the neuron generates an action potential to transmit the message.
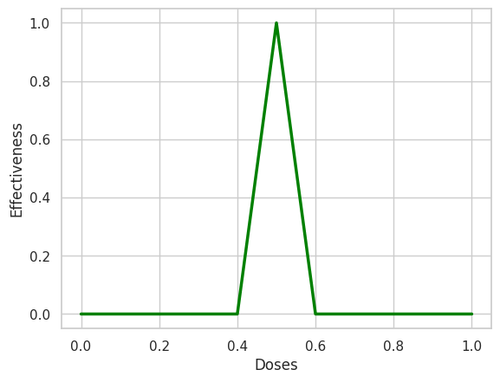
The all-or-none law of neural action potentials states that when the stimulation of a neuron reaches a certain threshold, a full action potential is generated; if the stimulation does not reach the threshold, no action potential is produced. In other words, the action potential either occurs completely or not at all, with no intermediate states.
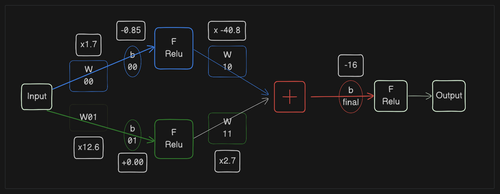
Here is a diagram showing the relationship between electrical stimulation (X) and the action potential response (Y):
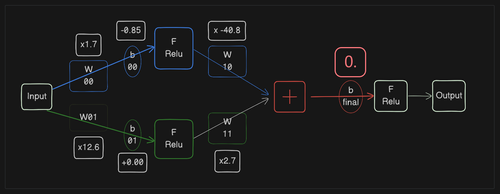
Although the simulation above looks ideal, in the real world, we won't have the parameters (e.g. Wij, Bij) in the model, nor will we know what the active function should look like.
To see how backpropagation works, let's erase a parameter(bfinal) value and see if we can 'train' the model by 'observing' the data to 'approximate' the real-world situation.
Modify bfinal from -16 to 0 and change the bfinal parameter to require gradients(requires_grad=True):
classBasicNN_train(nn.Module): def__init__(self): '''Define the layers of the network.''' super(BasicNN_train, self).__init__() ''' ... (the same) ... ''' # Final bias # Edit here self.b_final = nn.Parameter(torch.tensor(0.00), requires_grad=True) defforward(self, input_value): '''Define the forward pass.''' ''' ... (the same) ... '''
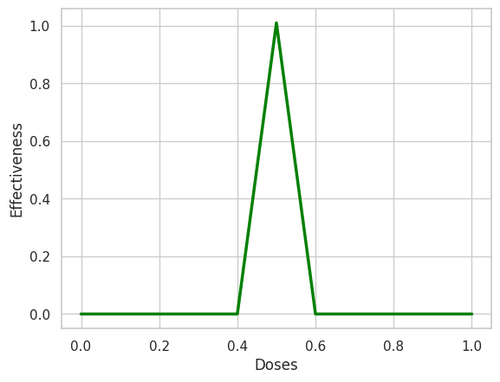
Now, the spikes of this neuron network look like below.
Figure 5. Response of the untrained model.
By observing the neuron's response, we know that the neuron will fire an action potential at a SPECIFIC stimulus potential.
Let's assume that the stimulus potential that triggers an action potential is 0.5, and the neuron will not respond to other stimulus potentials. We may get three data points based on our observation in the real world.
# Observed Data stimuli = torch.tensor([0.,0.5,1.]) response = torch.tensor([0.,1.,0.])
Let's train the neuron network with these data!
# Define the optimizer: Stochastic Gradient Descent optimizer = SGD(model.parameters(), lr=0.1) print("Final bias, before optimization: "+str(model.b_final.data)+"\n")
for epoch inrange(100): total_loss =0 for iteration inrange(len(stimuli)): stimuli_i, response_i = stimuli[iteration], response[iteration] output_i = model(stimuli_i) loss =(output_i - response_i)**2# It's mean square error here, which batch size is 1. # Calculate gradient, here is only for b_final loss.backward() total_loss +=float(loss) # Adapt b_final parameter optimizer.step() # Clear accumulated gradient and start another training loop. optimizer.zero_grad() # Observe the changes in "b_fianl" and the "loss" during each training epoch. print(f"Epoch {epoch+1} | Loss:{total_loss} | b_final: {str(model.b_final.detach())}")
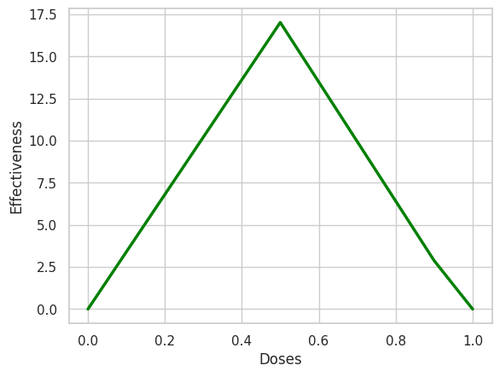
The responses of the trained model look like below:
Figure 6. Response of the trained model.
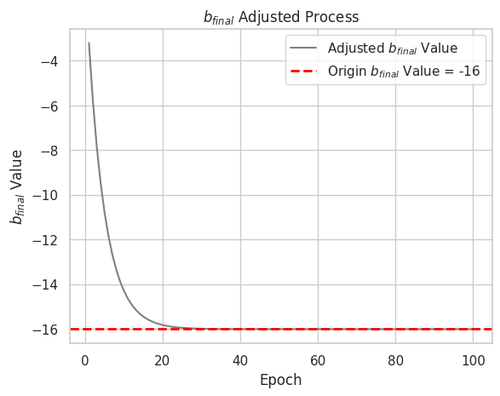
After optimization, bfinal fixed from 0 to -16.01, which approximates our assumed ground truth value of -16!🎉
The training process was repeated 100 times (Epoch = 100). In each training session, three observed data points were reviewed one by one. Each data point was input into the model for prediction and loss calculation. After accumulating the loss, the model parameters were adjusted. Overall, the training process includes four main steps: Forward, Loss Calculation, Backward, and Update Parameters.
Here, I will calculate the process for Epoch = 1 and show the results for all epochs at the end.
You can click on the corresspond data tab to view each data's calculations and verifications for each step.
To compute the loss, we measure the difference between the predicted value and the observed value.
In this example, we simplify the process by squaring the difference between the predicted value (Y^) and the observed value (Y).
The general formula for the loss function in this case is Mean Square Error(MSE):
Loss(Y^,Y)=i=1∑nN1(Y^i−Yi)2
However, given the high level of simplification in this example, each batch (i.e., the number of data points fed into the model each time) contains only one data point, so (N=1). Thus, the loss function simplifies to:
Using the loss value accumulated with all three data, the gradient, the optimizer, and the learning rate( learning_rate = η=0.1 ), determine how much the model parameters should be adjusted (in our example, it is bfinal being adjusted).
In this case, we use Stochastic Gradient Descent(SGD) as our optimization algorithm, which updates the parameter bfinal as follows:
n represents the number of batches. In this example, we have 3 batches (although each batch contains only 1 data point, this is specified to avoid confusion). After going through all the batches in one epoch, we update the parameters once.
Therefore, substituting the values:
updated_bfinal=0−0.1×(0+32.02+0)=−3.202
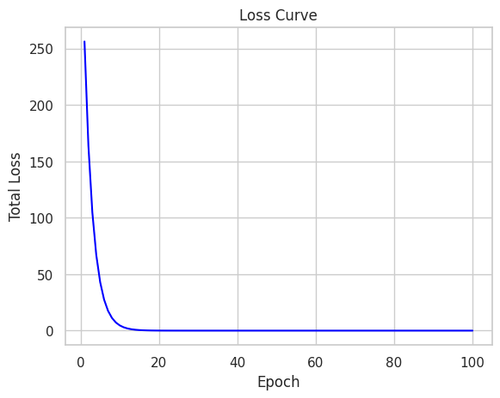
Through Figure. 8, we can see that with each epoch, the loss decreases as bfinal is adjusted.
Figure 8. Loss Curve.
Additionally, from Figure. 9, we can observe that bfinal gradually approaches the preset value of -16, eventually adjusting to -16.01.